お役立ち情報
AI入門|ディープラーニング(深層学習)と機械学習の違いとは?
良かったら”♥”を押してね!

OpenAI社のChatGPT、マイクロソフト社のCopilot、Google社のGemini・・・、これらのAIサービスは無料でできるものも多く、私たちの日常生活にもすっかり馴染んできています。
生成AIに興味をもって色々と調べていくと「ディープラーニング」という言葉を聞くこともあるのではないでしょうか?AIといえば機械学習というイメージが強いですが、ディープラーニングと機械学習はどう違うのでしょうか?
今回はそんな疑問を、AI初心者さん向けに分かりやすくまとめていきます。ぜひ、参考にしてみてくださいね。

※本記事は2024年7月8日に公開した内容を、最新の情報にアップデートし公開しております。
目次
1.機械学習とは?
機械学習とは、簡単にいうと「機械(コンピューター)が学習し、判断や予測をできるようにするAI技術」です。
さまざまな学習スタイル(=機械に知識をどう教えるか)と、モデル構造(=機械がどう考えるか)を組み合わせることで、機械が人の代わりに判断や予測をおこなえるようになります。
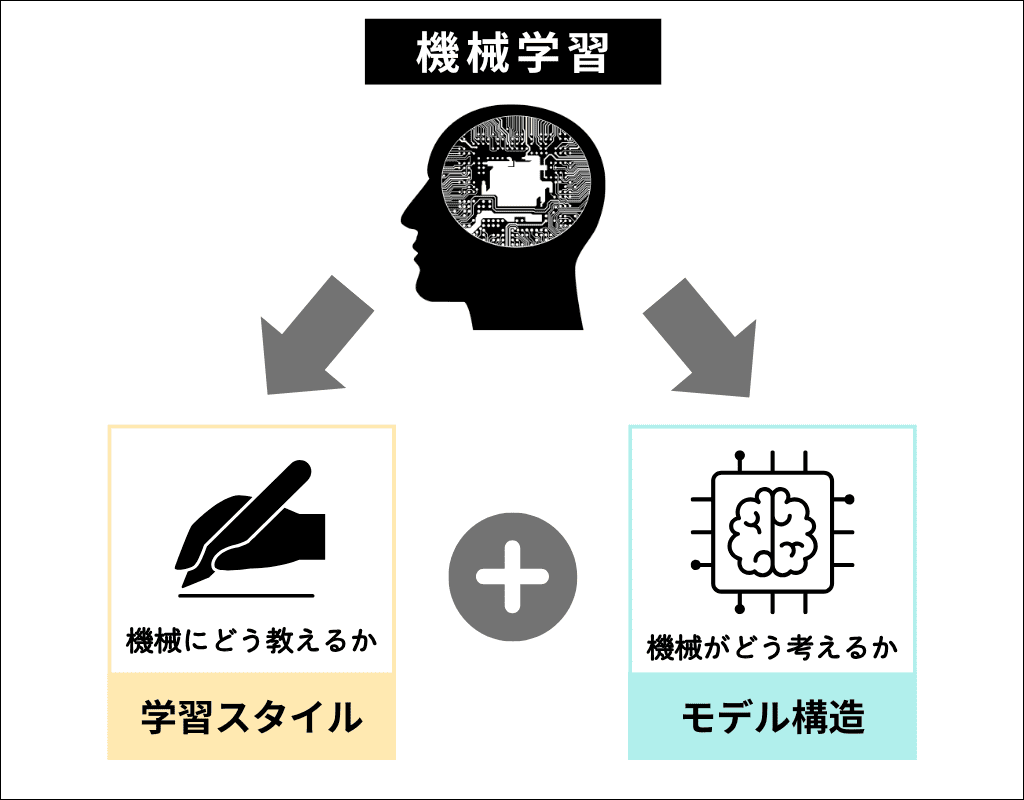
機械が学んで考えることがセットになったものが機械学習であり、どちらか1つで成り立つわけではないということですね。(この軸が理解を深めるうえで非常に重要なポイントになります)
そして、多くの方が疑問に思っている「機械学習とディープラーニングはどう違うの?」という問いの答えは、「ディープラーニングは機械学習の一部」になります。もっというと、モデル構造(=機械がどう考えるか)の一種です。
この点を分かりやすくするために、まずは機械学習の「学習スタイル」と「モデル構造」には、どのようなものがあるのかを解説しますね。
※すでに、このあたりの理解はできている!という場合は、「2.ディープラーニングとは?」へジャンプしていただいて大丈夫です。
1.1. 機械学習の種類(学習スタイル編)

まずは、機械にどうやって知識を教えるかという「学習スタイル」についてご説明します。
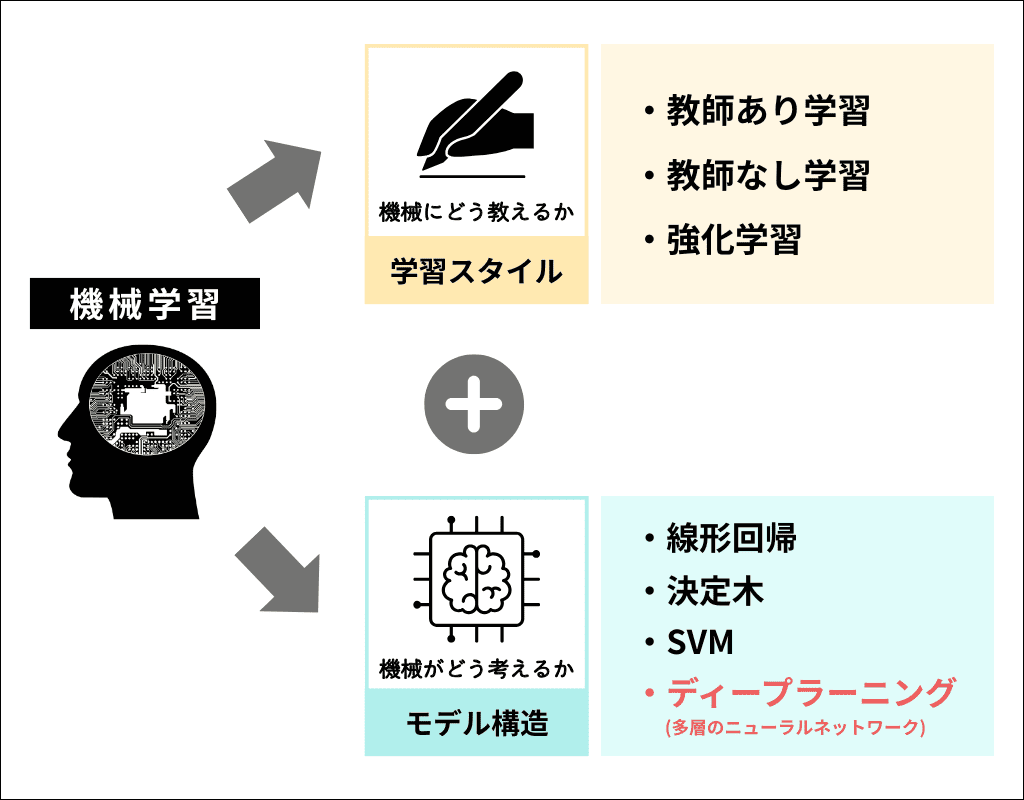
一般的な機械学習の学習スタイルは、以下の3つになります。
※以下は、機械にどうやって知識を教えるかという「教え方」の種類になります。なので、学校の先生を思い浮かべていただけると分かりやすいかもしれません。
- 教師あり学習
- 教師なし学習
- 強化学習
それぞれ、どういうものなのかをまとめてみます。
教師あり学習
教師あり学習とは、入力するデータとそれに対する正解(答え)をセットで学習させる手法です。
たとえば、「『1+1=』と出てきたら『2』と返すのが正解だ」と教えておくことで、同じことを聞かれた場合に「2」と答えられるように学習させるのが教師あり学習の特徴です。
正解や不正解が明確に決まっている問題を人に代わって機械で解決する場合に、この教師あり学習が役に立ちます。
教師なし学習
教師なし学習とは、正解を与えない学習手法です。入力データだけを読み込ませ、そこから機械側で法則や規則性、パターンを見つけ学習していきます。
この学習方法は、まだ人が見つけられていない共通点や規則性、パターンを見つけ出すのに役立ちます。
強化学習
強化学習とは、機械が自ら行動を選び、その結果に対して報酬を受け取りながら「より多くの報酬を獲得するにはどうすればいいか」を自ら学習していく方法です。
最終的に達成したいことは決まっているけれど、そこにたどり着く手段や方法は多数ある(正解が決められない)場合に、この学習方法が役立ちます。
| 学習スタイル | できること |
|---|---|
| 教師あり学習 | 人がおこなう作業をAIで代行(正解が明確な事柄) |
| 教師なし学習 | 人が発見しきれていない法則やパターン・構造をAIで発見 |
| 強化学習 | 最終的な目的に対して、最適な手段や行動をAIで発見 |
***
このように、機械学習における学習スタイルには色々な種類があり、利用目的に合わせて適切な方法を選択します。
1.2. 機械学習の種類(モデル構造編)

次にモデル構造(=機械がどう考えるか)についても簡単にお話していきます。
モデル構造にはたくさんの種類があるため、すべてに触れてしまうととても専門的でややこしくなってしまうので、ざっくりとイメージしやすいように有名なモデル構造を例に挙げながら解説していこうと思います。
機械学習をおこなう場合、与えられたデータをどのように組み立てていくか(考えていくか)の手法には種類があります。
■代表的なモデル構造の一例
- 線形回帰
- 決定木(ディシジョンツリー)
- ランダムフォレスト
- SVM(サポートベクターマシン)
それぞれの特徴を簡単にまとめてみます。
線形回帰
線形回帰とはもっとも基本的な予測モデルと言われており、 数値の傾向を直線で表すアルゴリズムで、データを予測する際に利用されます。
たとえば、小売・サービス業や金融業などの売上や需要予測に使用されるケースが多いです。
決定木(ディシジョンツリー)
決定木では、「もしこうなら、こう」と、条件を分岐させて判断します。決定木も予測モデルですが、線形回帰との大きな違いは、はい・いいえの分岐のみで予測をする点にあります。たとえば顧客の行動を予測したり、リスクを分析したりする際に活用されます。
ランダムフォレスト
ランダムフォレストとは、決定木を複数組み合わせ、さらに精度や安定性を高めたモデル構造です。複数のモデル構造を組み合わせて精度を高めることをアンサンブル学習と呼んでいるのですが、ランダムフォレストはそれを活用したモデル構造となります。
SVM(サポートベクターマシン)
グループ分け(クラス分け)をする際に、最も効果的な境界線を導き出すモデル構造です。SVMはデータの次元が大きくなっても精度を高く維持でき、汎用性ある点が特長です。たとえば 災害予測や、顔検出、株価予測、といった場面で活用されているモデル構造になります。
***
このように、モデル構造には様々な種類があり、強みや弱みも異なります。そのため、用途に合わせて使い分けることが大切です。
先ほどご説明した学習スタイルと、このモデル構造を組み合わせて機械学習が成り立ちますが、モデル構造によっては特定の学習スタイルしか実用的に利用できないなどの特徴もあります。(例:線形回帰は基本的には教師あり学習、など)
2.ディープラーニングとは

次に、本題の「ディープラーニングとは」というお話をしていきましょう。
ディープラーニングは「深層学習」とも呼ばれ、機械がどのように考えるかを決める「モデル構造」の一種になります。
先ほどご説明した、「線形回帰」「決定木」「SVM(サポートベクターマシン)」 などと同じ仲間であり、特に、画像や音声認識、自然言語処理といった複雑なデータを処理することに優れています。
ここであらためて、「機械学習とディープラーニングはどう違うの?」という問いの答えを整理してみましょう。
冒頭でもお話した通り、この問いの答えは「ディープラーニングは機械学習の一部」になります。
ディープラーニングは自ら学ぶ特性があることから、「教師あり学習」や「教師なし学習」「強化学習」などの学習スタイル(=機械に知識をどう教えるか)の一種のように表現されるケースもありますが、厳密にはモデル構造(機械がどう考えるか)のひとつです。
そして機械学習は、「学習スタイル」と「モデル構造」を組み合わせて成り立つ仕組みなので、「ディープラーニングは機械学習の一部 」と表現することができます。
つまり、機械学習とディープラーニングは並べて比べるものではなく、機械学習のなかにディープラーニングというモデル構造がある、というイメージになります。
3.ディープラーニングの仕組み
近年、急速に進化しているA技術Iの裏側には、このディープラーニングが深く関わっています。ここからは、ディープラーニングがどういった仕組みのモデル構造なのかについて詳しく解説していきます。
ディープラーニングは、人間の脳の仕組みを真似た「ニューラルネットワーク」 という考え方を応用したモデル構造です。
ニューラルネットワークは、人間の脳にある神経細胞(ニューロン)の働きを模倣した構造をしており、情報を伝え合いながら複雑な判断を行えるようになっています。この仕組みによって、より人間に近い思考や考え方を持つ点が、ディープラーニングの大きな特長です。
たとえばChatGPTを使うと、人間と会話するようにAIとチャットをおこなうことができると思いますが、この仕組みのベースに使用されているのもディープラーニングになります。
人間のニューロンを模倣したとされるニューラルネットワークは主に以下の3層から構成されています。
- 入力層:データを受け取る層
- 隠れ層:データを加工したり変換したりする層
- 出力層:最終的な予測・判断を出力する層
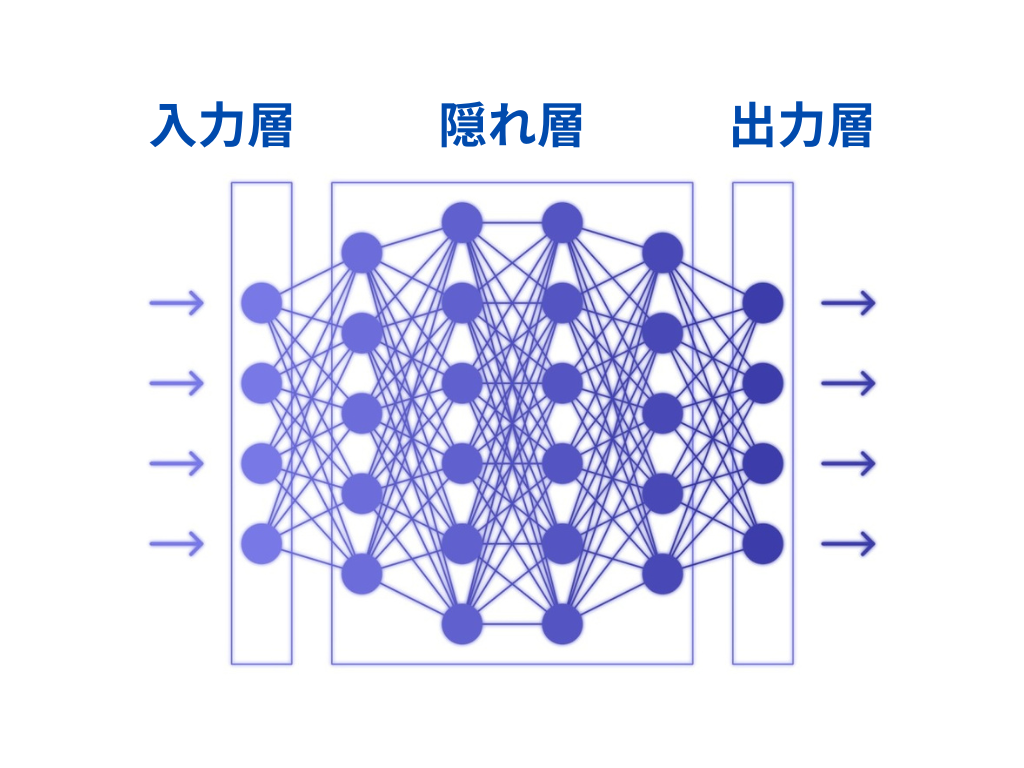
たとえば画像認識をおこなう場合、入力層で元となるデータを受け取り、隠れ層でそのデータを変換し、出力層で何が映っているかを決定するという流れになります。
そしてこの「隠れ層」が何層にも積み重ねられた多層である点がディープラーニングの特徴であり、「ディープ」と表現される理由でもあります。
ニューラルネットワークの隠れ層を積み重ねたものを「ディープニューラルネットワーク」と表現しますが、ディープニューラルネットワークによって隠れ層が多層になればなるほど、 お互いに情報を補いながら予測、分析、分類を最適化することができます。
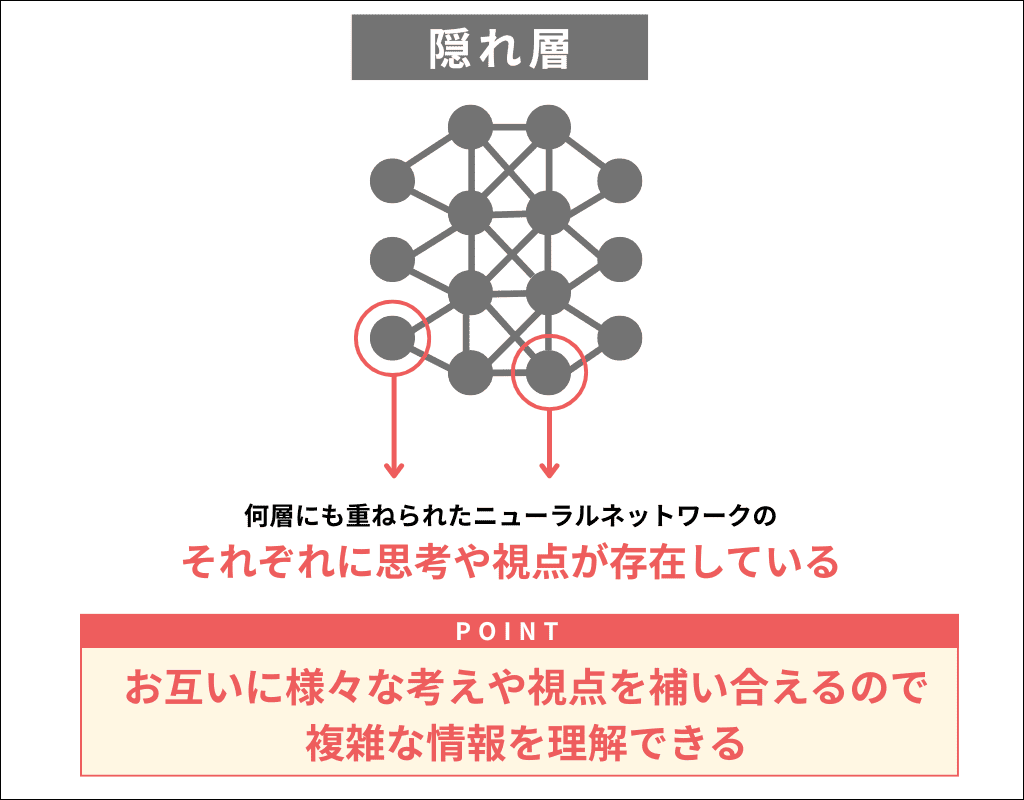
このディープニューラルネットワークにより、コンピューターはデータの特徴をより深く学習することができるようになるため、従来よりも複雑なデータを分析できるというわけです。
先ほどご紹介した線形回帰や決定木といったモデル構造は、基本的に1つの考え方に基づいて判断を行うため、モデル構造の中で複数の思考や視点を補い合うような処理は得意ではありません(ただし、異なるモデルを組み合わせる「アンサンブル学習」として補完することは可能です)
一方、ディープラーニングでは、隠れ層を何層にも重ねることで、構造そのものが複数の思考や視点を分担・連携するように設計されており、それによってより柔軟で高精度な学習が可能になっています。
さらにこの仕組みにより、人が用意しなければいけない学習データがよりシンプルになった点も、ディープラーニングの強みです。
ディープラーニングが登場する前の、線形回帰、決定木、SVMといった一般的なモデル構造の場合は、人間があらかじめ「特徴量」を指定しなければなりませんでした。特徴量とは、コンピューターが物事を認識するときの基準となる特徴のことです。
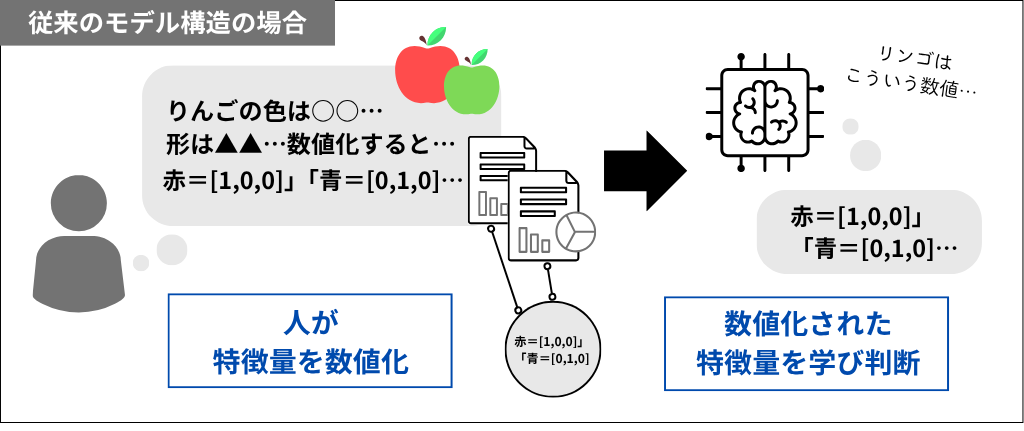
たとえば、リンゴの画像認識であれば、「色」「形」などが特徴量になります。もともとは、「色」や「形」といった特徴を人間があらかじめ数値化して与える必要がありました。
一方、ディープラーニングでは、「これがリンゴの画像です」とだけ教えれば、コンピューター自身が「なるほど、赤くて丸いものがリンゴか」という形で特徴を自動で見つけて学習してくれます。
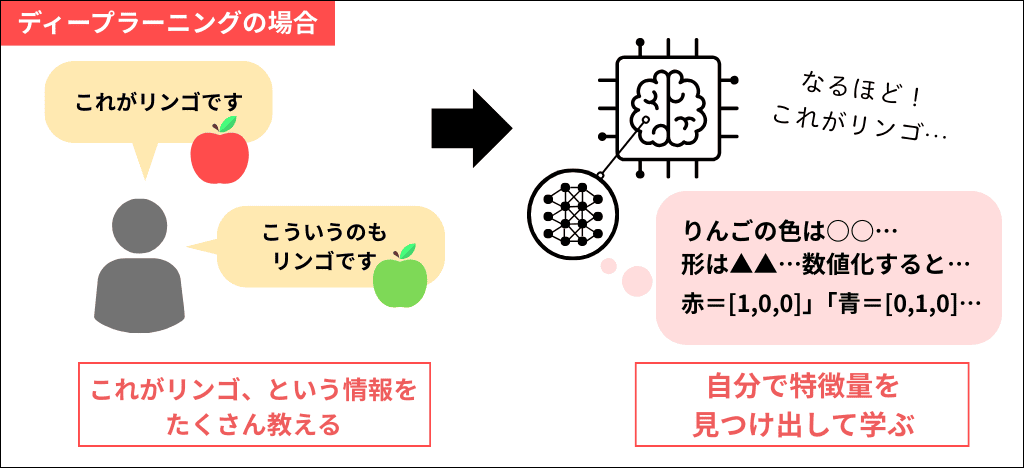
このように、人による前処理の手間がほとんどなく、より精度の高い分析が可能になる点がディープラーニングの特長でもあります。
4.ディープラーニングでできること

では、ディープラーニングを活用することで具体的にどのようなことができるのでしょうか?
ディープラーニングの強みの1つは、人間による特徴量の抽出が不要になる点です。そのため、特徴量の数値化が難しい分野においてその強みを発揮しています。
ここでは、とくにディープラーニングが得意としている以下の3つについて解説していこうと思います。
- 画像認識
- 音声認識
- 自然言語処理
1つずつ見ていきましょう。
4.1. 画像認識
写真などの画像は、ピクセル単位で情報が存在するためデータ量がとても膨大になります。また、同じカテゴリの対象物であっても個体差や置かれている環境の違いによって色味や輪郭等の特徴に違いが発生するため、特徴量の数値化がとても難しいとされています。
この場合に、ディープラーニングによる画像認識が力を発揮するというわけです。
画像認識は、画像データからパターンや特徴、物体などを自動的に抽出する技術です。画像認識は、さまざまな分野で導入されています。
たとえば、身近なところで考えると、スマートフォンの画面ロックは顔認証が使われていますよね。
他にも医療分野では、病変と思われる箇所を自動的に検知・検出する技術が使われていたり、自動車業界では、自動運転で歩行者や標識などを自動検出する技術が使われていたりします。
ディープラーニングを活用することでより高精度の分析が行えるため、人の目では見逃してしまうような小さな異変も認識できます。
4.2. 音声認識
音声データは、たった5秒であっても数万のサンプル数になると言われており、データ量が膨大です。また、同じ言葉でも発した人の状況や状態によってデータが変動するため、特徴量を数値化することが難しい分野になります。
そこで、ディープラーニングの音声認識が役立ちます。音声認識とは、人が話す音声をテキストに変換する技術です。
たとえば、音声認識はスマートフォンの音声アシスタントや音声入力に用いられています。
他にも、自動で議事録を作成してくれるアプリや問い合わせ内容を書き起こすシステムなどに使われています。最近では、コールセンターにおける自動対応の一環でディープラーニングを活用する事例などもあります。現在は、希望する問い合わせ窓口のダイヤルを選択するのが一般的ですが、「○○に関するお問い合わせ」と電話で話すことで、自動的に窓口を振り分けるシステムなども出てきています。
ディープラーニングを活用することで、数値化しきれない音声の微細な特徴を捉えることができ、ユーザーとのスムーズな会話を実現できるというわけなんですね。
4.3. 自然言語処理
自然言語とは、私たちが普段生活のなかで当たり前のように使っている言語のことです。自然言語は、単語の数がとても多く、前後の文脈によって細かく意味合いが変動するため、抽象的な情報が多数含まれます。そのため、特徴量の数値化が難しい分野になっています。
そして、自然言語を処理する場合にも、ディープラーニングが活躍します。
自然言語処理とは、人間が使う日常的な言語をコンピューターに処理させる技術です。自然言語処理は、テキストデータの文脈や意味を理解して処理します。
たとえば、言語翻訳やチャットボットは、ユーザーが入力した情報をもとに適した答えを返してくれます。他にも、メールフィルターは、メールの文章を解析して、怪しいメールは迷惑メールやスパムとして分類してくれますよね。
最近話題のChat GPTはまさにディープラーニングを用いた、自然言語処理の人工知能です。非常に滑らかに言語を使うため、人とチャットしているような感覚になります。
自然言語処理自体は、ディープラーニングが登場する以前から、決定木や線形回帰などのモデル構造によって対応可能でした。たとえば、お問い合わせ用のチャットボットなどは以前から見たことがあるかと思います。
しかし、文章の意味や文脈といったあいまいで複雑な情報を「特徴量」として数値化し、機械に学習させるには限界もあり、融通が利かない会話になってしまったり、思った回答が返ってこなかったりする場合なども多々ありました。
ディープラーニングの登場によってこの課題が軽減され、自然言語処理の精度と柔軟性は飛躍的に進化したとされています。
***
このように、ディープラーニングの登場によって「機械に理解してもらうことが難しいとされていた分野」についても機械学習が進み、私たちの生活のもっと身近なところで「精度の高いAI技術」が利用されるようになってきている、というわけなんです。
5.ディープラーニングのメリット
ディープラーニングはAI界の常識を覆す素晴らしい技術ですが、メリットとデメリットの両方が存在することも忘れていけないポイントです。
ここからは、ディープラーニングにはどういったメリットがあるのかについて整理してきましょう。後に続くデメリットも、理解を深めるうえで非常に重要なのでぜひ併せてチェックしてみてくださいね。
■ディープラーニングのメリット
- 数値化やルール化が難しい分野に強い
- 機械学習を効率化できる
- ビックデータと相性が良い
順番に解説していきます。
5.1.数値化やルール化が難しい分野に強い
前述したとおり、ディープラーニングはニューラルネットワークを何層にも重ねることで自ら特徴量を抽出できるようになりました。
そのため、人間では数値化できない分野であっても、コンピューター側で理解することができる点が大きなメリットです。
特徴量の数値化だけなく、規則性の発見やルール化についても同様のことが言えます。曖昧で不安定な「ルール化するのが難しい事柄」に対しても、コンピューターが自らそれを学んで理解できるようになりつつあります。
このように、人間が数値化して教えきれないことを自ら学んだり、人間では見逃してしまうような複雑なルールを発見できたりする点は、ディープラーニングのメリットと言えるでしょう。
5.2. 機械学習を効率化できる
ディープラーニングは、複雑に絡み合った大量のデータからルールや重要な特徴を自ら探していくため、学習(トレーニング)には時間がかかります。
しかしその一方で、人間が特徴量を設計したり、学習データを細かく前準備したりする必要がほとんどなくなったため、従来の機械学習と比べて開発工程は大幅に効率化されました。
また、学習させるデータ量が膨大であればあるほど精度が高まるため、チューニングも効率化されます。ここでのチューニングとは、より精度高く学習できるようにモデル構造やアルゴリズムを調整することです。意図しない学習をしてしまった場合の修正や、さらなる最適化を目的として行われます。
ディープラーニングは自分で考えながら精度を高めていく能力があるため、人間によるチューニングが最低限で済み、全体の効率化につながります。
5.3. ビックデータと相性が良い
ディープラーニングを活用するためには、大量のデータを学習させる必要があります。そして、データの量が増えれば増えるほど、精度が高まるという特性を持っています。
ビッグデータとは、人間では全体を把握しきれないほどの膨大なデータの集まりを指します。こうした膨大なデータを活用することで、格段に高い精度でパターンやルールを見つけ出せる点も、ディープラーニングの大きなメリットです。
またディープラーニングは、一度大量のデータで学習を済ませてしまえば、「学習済みモデル」として他のタスクや場面でも汎用的に活用できます。
ビッグデータを処理するため、学習には時間がかかりますが、一度学習してしまえば、あとは学んだ知識をもとに推論処理をするだけになるため、回答は高速かつ実用的です。これは、かの有名なChatGPTでも採用されている方式です。
さらに、ディープラーニングは、ビッグデータを多角的に理解できる能力があるため「表現は違うけど意味やニュアンスは同じ」といったケースでも柔軟に対応できます。そのため、たとえば質問の仕方が微妙に変わっても、返ってくる回答に一貫性と意味の整合性を保つことが可能です。
こうした観点から、ディープラーニングはビッグデータを最大限に活用できる高度なモデル構造と言えます。
6.ディープラーニングのデメリット

それでは、ディープラーニングにはどのようなデメリットがあるのでしょうか。主なデメリットは以下になります。
■ディープラーニングのデメリット
- 膨大なデータと高い処理能力のコンピューターが必要
- 時間とコストがかかる
- ブラックボックスになりやすい
- 完璧ではない
こちらも1つずつ確認していきましょう。
6.1. 膨大なデータと高い処理能力のコンピューターが必要
ディープラーニングは、学習するデータが大きくなればなるほど、精度が高くなる特性がありますが、その一方で、十分なデータ量が担保できない場合には本来の性能を発揮しづらく、期待した成果が得られないこともあります。
また、ビッグデータを処理することができる高性能な計算処理が可能なコンピューターも必要になります。特に、並列処理に優れているGPU※の性能がカギを握っています。 なぜならディープラーニングでは、大量のデータを一斉かつ反復的に並行処理する必要があるのですが、これをメインで処理するのがGPUだからです。
何層にも重ねられたニューラルネットワークを一度に処理することを考えると、高速な並行処理が必要だというイメージが湧きやすいのではないかと思います。
このように、ディープラーニングを活用するためには、ビッグデータと、ビッグデータを処理することができる高性能なGPUを搭載したコンピューターが必要になるため、開発環境を整えるハードルが高い点がデメリットの1つになります。
AIが普及すると同時に、GPUという言葉を聞く機会も増えています。そして似た言葉にCPUという言葉もあります。両者の違いはざっくりこんなイメージです。
・GPUとは
GPUとは、Graphics Processing Unitの略語で、日本語では「画像処理装置」という意味になります。指示された処理を一斉に、かつ大量に高速で繰り返す「並列処理」が得意な点が特長で、CPUからの指示で動く筋肉のような存在です。そのため、ビッグデータを反復的に並列処理する必要があるディープラーニングにおいてGPUは非常に重要な役割を担っています。
・CPUとは
CPUとは、Central Processing Unitの略語で、日本語では「中央演算処理装置」という意味になります。コンピューター全体の司令塔で脳のような存在です。複雑で多様な処理が可能となっており、GPUを始めとする様々なパーツに指示を出します。
6.2. 時間とコストがかかる
ディープラーニングのデメリットとして、時間とコストがかかる点も挙げられます。
ディープラーニングでビッグデータを学習するにはそれなりの時間が必要ですし、大量のデータを扱うための高性能なコンピューターを準備するには、莫大なコストがかかります。
さらに、ディープラーニングの精度を維持し高めていくためには、 継続的な学習が必要になるため、一時的なコストだけでなくランニングコストがかかる点にも注意が必要です。
ここでのコストとは、費用面だけでなく、人的リソースも含めた全体的なコストになります。ディープラーニングの実用性を担保するためには、人間による検証も必要になるためです。
専門性の高い人材採用が求められる点なども含め、時間やコストがかかる点も、ディープラーニングのデメリットの1つでしょう。
6.3. ブラックボックスになりやすい
ディープラーニングは、自分自身で特徴量を見出し、学ぶ姿勢が強い特性がある一方で、「なぜこの答えが導き出されたのか」というプロセスや根拠がブラックボックス化してしまいます。
この点もディープラーニングの代表的なデメリットになります。
特徴量を人間が準備して学習させる場合は、機械が導き出した判断の根拠を説明することができますが、特徴量の抽出から機械がおこなっているディープラーニングではそれが難しいというわけです。
そのため、ディープラーニングによって導き出された判断が、本当に正しく機能したうえでの結果なのかの検証や説明が難しく、ビジネスでの利用時や、根拠を明確に説明する必要がある場面ではまだまだ課題が残されています。
6.4. 完璧ではない
最後に、とても大切なポイント「完璧ではない」という点も、ディープラーニングのデメリットです。
何でも自分で考えてくれるからこそ誤認してしまいやすいですが、ディープラーニングは完璧ではなく、間違えることもあります。
現に、「破局的忘却」と呼ばれる現象が起きることが確認されています。破局的忘却とは、学習済みのニューラルネットワークに、新しく別の知識を与えることで、過去に学習したことを忘れてしまう特性になります。
ディープラーニングは、これまで学んだことを複雑に掛け合わせながら自ら考えることができる特性がある分、新しいデータを学習した際に、過去の学習データの重要度を更新してしまうことがあるため、こうした現状が起きることがあります。
取り扱う情報が高度になればなるほど、人間側で「完璧ではないこと」に気づきにくくなるため、ディープラーニングを活用する際は、限界や特性を理解したうえで、慎重に利用することが求められます。
7.まとめ:ディープラーニングは人間に近い思考を持つ機械学習
今回はディープラーニングと機械学習の違いや、ディープラーニングの特徴やメリット・デメリットについて解説してみました。
数値化するのが難しかった特徴を自ら学んでくれるようになった、いわば“人間の脳に近い構造”を実現したディープラーニングによって「機械には人の気持ちを理解できない」という常識が覆されつつあります。
実はこのディープラーニングという概念自体は、かなり以前から存在していましたが、それを可能にするIT技術や高性能なコンピューター環境を整えることが難しかった点などから、なかなか実用化されてこなかった歴史があります。
しかし昨今ではデジタル化・DX化が急速に進み、時代とともにビッグデータを扱う場面も増え、それを処理できる高度なコンピューター技術も生まれています。こうした環境的要因も、ディープラーニングが一気に進化した理由と言えるでしょう。
こうしたAI技術とうまく付き合い、上手に活用していくためにも、私たち自身がAIとはどういうものなのか・どんなデメリットやリスクがあるのかを常に考えて学びながら、安全に利用できる環境を作っていく姿勢も大切です。
私も最新の情報やトレンドをチェックしながら、AIについて理解を深めていきたいと思います。今後ますます進化していくAI技術が秘めた無限の可能性から目が離せません。

WWGのブログ記事作成専門チームに所属するWebライターです。ホームページ制作やWeb・AIに関することをはじめ、デザイン・コーディング・SEO・人材採用・ビジネス・地元についてのお役立ち情報やニュースを分かりやすく発信しています。【最近のマイブームはChatGPTと雑談をすること】
この人が書いた記事をもっと見る
![]() おすすめ記事のご紹介
おすすめ記事のご紹介




各種SNSでも情報発信中♪
